Appearance
统计分析基础入门
欢迎使用Q11E速填通!本教程将帮助你快速理解统计分析的核心概念,让你能够顺利使用系统生成符合需求的模拟数据。
本教程能帮你解决什么问题
使用Q11E系统SEM页面生成数据时,你会看到很多统计指标。理解这些概念的含义,你才能:
- 知道如何配置参数:设置什么样的变量类型、关系方向,才能生成符合研究假设的数据
- 判断数据是否合格:看懂系统输出的分析结果,知道什么样的数据合适于研究
1. 核心概念:量表
在问卷调查中,我们经常需要测量一些看不见、摸不着的东西,比如"学习动机""满意度""压力水平"等人们的主观性意愿。这些主观感受无法直接测量,需要通过一系列问题来间接量化,这一系列问题加上评分标准就是量表。假设你想测量"学习动机",可能会设计这样的量表:
请根据你的实际情况,选择最符合的选项:
我对学习很感兴趣
- 非常不同意(1分) 不同意(2分) 一般(3分) 同意(4分) 非常同意(5分)
我会主动学习新知识
- 非常不同意(1分) 不同意(2分) 一般(3分) 同意(4分) 非常同意(5分)
我享受解决问题的过程
- 非常不同意(1分) 不同意(2分) 一般(3分) 同意(4分) 非常同意(5分)
这就是一个3题项的5级量表。
2. 核心概念:维度
一个问卷通常包含多个量表,每个量表测量一个概念,这个概念就是一个"维度"(或者变量/成分/因子)。在统计分析中,维度有不同的角色定位:
| 类型 | 说明 | 例子 |
|---|---|---|
| 自变量 | 原因变量,影响其他变量 | 学习时间、教学方法 |
| 因变量 | 结果变量,被其他变量影响 | 学业成绩、满意度 |
| 中介变量 | 中间变量,传递影响 | 学习动机、注意力 |
| 调节变量 | 影响关系强弱 | 性别、年龄、基础 |
配置维度时,你需要设置:
| 属性 | 说明 | 设置建议 |
|---|---|---|
| 维度标识 | 变量的简称 | X、Y、M、W等 |
| 变量类型 | 维度在模型中的角色 | 取决于假设模型 |
| 小题数 | 该维度包含的题目数量 | 取决于问卷的内容 |
| 均值 | 该维度的平均得分 | 1到量表水平之间 |
- 一个量表包含多个题项
- 一个维度对应一个量表
- 多个维度共同构成你的研究模型
3. 信度与效度
信度(Cronbach's α系数)
信度是量表测量的一致性和稳定性。如果你的量表用5道题测量"学习动机",信度高说明一个人在这5道题上的得分比较一致。背后的数学公式不要求掌握,但我们需要知道量表通常需要做信度分析,信度不过,论文也难过。一般学术界认为信度>0.7属于可接受范围。
效度
效度回答的是:量表有没有测对东西。比如你想测"学习动机",但题目问的是"学习投入",那就测偏了。听起来有点抽象?笔者最开始看到别人这么写的,我听起来也云里雾里,不如用一个具体例子来理解。
有一份学习相关的问卷,包含三个维度,选项都是 “非常不同意” 到 “非常同意” 的 5 级评分:
- 学习投入(维度 1,4 题): 我能主动安排学习时间、我上课能专心听讲、遇到难题我会主动解决、我愿意为学习付出努力
- 学习动机(维度 2,5 题): 我对学习有兴趣、我想取得更好的成绩、我希望通过学习提升自己、学习能帮我实现目标、我会主动学习感兴趣的内容
- 学习满意度(维度 3,4 题): 我对自己的学习状态满意、我觉得学习效率还不错、学习让我有积极的感受、我对整体学习效果满意
对收集到的样本数据做效度分析(探索性因子分析,EFA),一份 “完美” 结果应该像这样:
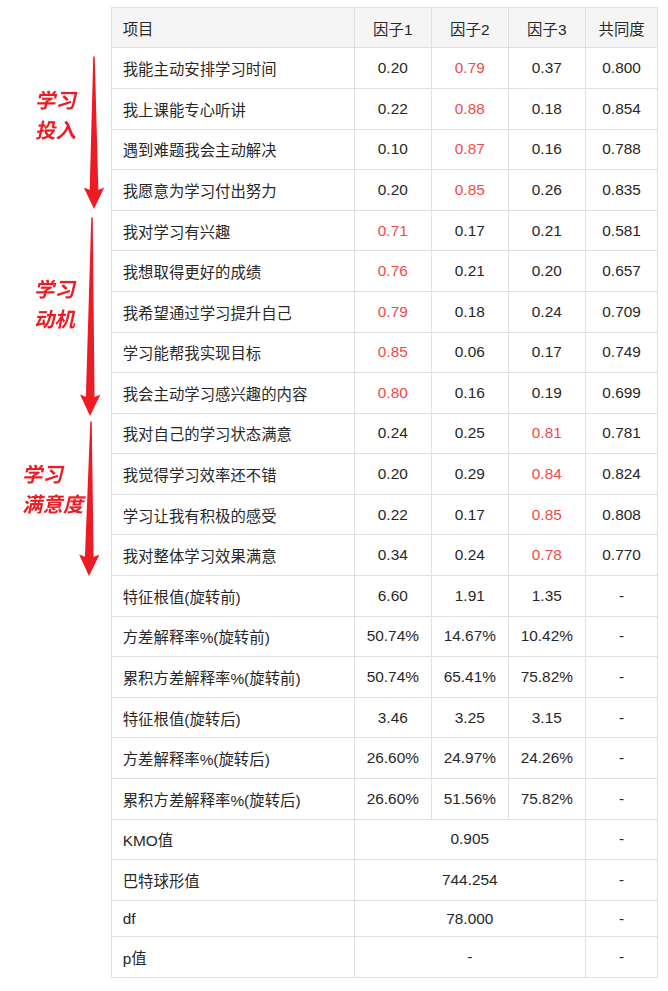
这张图怎么看?它其实是在告诉我们:同一列红色数字对应的题目,属于同一个维度。
理想情况下,效度分析会把所有题目重新归类:
- 维度 1(学习投入)的 4 道题,会清晰地聚在 “因子 2” 下;
- 维度 2(学习动机)的 5 道题,会全部归到 “因子 1” 下;
- 维度 3(学习满意度)的 4 道题,会全部归到 “因子 3” 下。(具体是因子几不重要,重要的是属于同一个因子。)
这就是效度好的表现:每个维度的题目都聚在一起,维度之间界限清晰。同时KMO>0.7,总方差解释率良好,这份效度分析完美过关。
反之,如果效度差,题目就会 “乱成一团”。比如 “我能主动安排学习时间” 被划分到了因子 1,和 “学习动机” 的题目混在一起,这就说明:你以为这道题在测 “学习投入”,但它实际测的是 “学习动机”—— 量表设计出了问题。
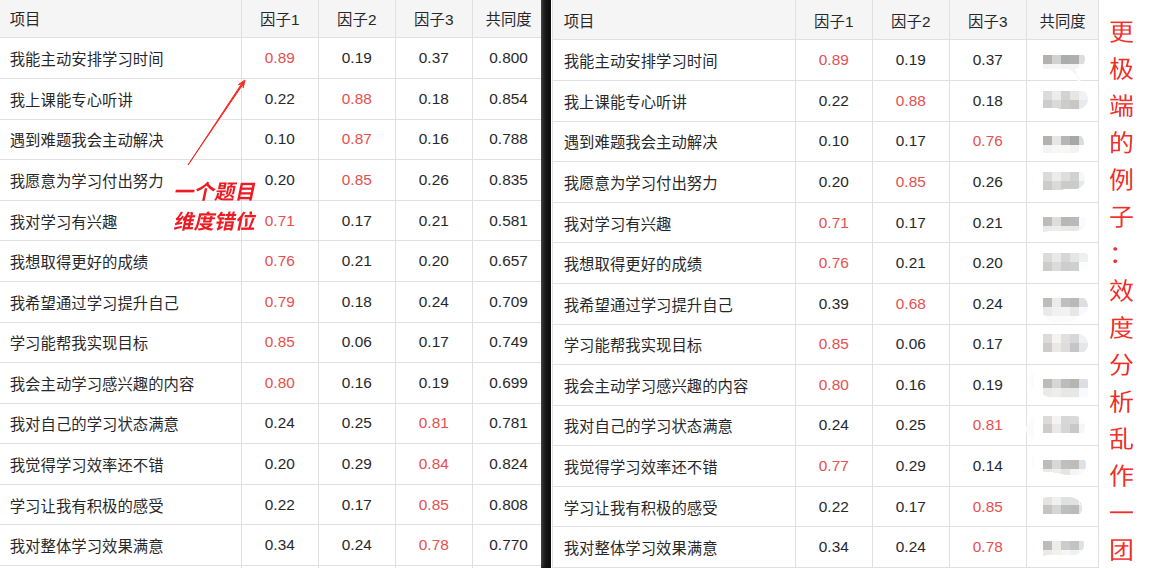
但在本数据模拟系统中,情况完全不同:
系统会严格按照你预先划分的维度来生成模拟数据,而不会去关心这些题目 “理论上” 应该测量什么。也就是说,你在问卷结构里把 “我能主动安排学习时间” 放在 “学习投入” 维度下,系统就会生成它属于 “学习投入” 的数据,不会出现现实调研中那种 “题目跑到别的维度” 的效度问题。
4. 相关分析
相关是两个维度之间的关系程度,相关分析回答:维度A变化时,维度B会跟着变化吗?
| 类型 | 含义 | 例子 |
|---|---|---|
| 正相关 | A增加,B也增加 | 学习时间越长,成绩越好 |
| 负相关 | A增加,B减少 | 玩游戏时间越长,成绩越差 |
| 无相关 | A变化与B无关 | 学号与成绩 |
相关不等于因果。两个维度相关,不代表一个维度导致另一个维度变化。
5. 回归分析
回归是用一个维度预测另一个维度,回归分析回答:已知维度A的值,能预测维度B的值吗?
核心概念
- 自变量X:用来预测的维度(原因)
- 因变量Y:被预测的维度(结果)
回归会得到一个方程,比如:成绩 = 30 + 5 × 学习时间
意思是:每多学1小时,成绩提高5分。
判断标准
| 指标 | 含义 | 期望值 |
|---|---|---|
| 系数β | 影响程度 | 数值越大,影响越大 |
| p值 | 是否显著 | p < 0.05表示显著 |
| R² | 解释力度 | 越大越好,> 0.3即可 |
6. 中介效应
中介是一个变量通过另一个变量影响其他变量(A通过B影响C)。中介效应回答:自变量是如何影响因变量的?
如:压力 → 睡眠质量 → 工作表现。压力会影响工作表现,但压力是通过影响睡眠质量,进而影响工作表现的。这里"睡眠质量"就是中介变量。
7. 调节效应
调节是关系的强弱取决于第三个维度,调节效应回答:A对B的影响在什么情况下更强或更弱? 调节变量 = 改变 “关系强弱” 的变量。A 对 B 的影响,有时强、有时弱,是谁决定强还是弱?就是调节变量。
生活中的例子
压力 可能导致 抑郁。有的人压力一大,立刻崩溃抑郁;有的人压力再大,也没事。为什么?因为中间有个东西在调节:社会支持(朋友、家人、安慰)
- 社会支持高,压力对抑郁的影响较小
- 社会支持低,压力对抑郁的影响较大
所以,社会支持 调节了 压力→抑郁 的关系强度
中介与调节的区别
| 特征 | 中介 | 调节 |
|---|---|---|
| 作用 | 解释如何影响 | 解释何时影响 |
| 位置 | 在A和Y之间 | 与A、Y同时作用 |
| 问题 | A通过什么影响Y | A的影响在什么条件下变化 |
8. 差异性分析
差异性分析是比较不同组别之间是否有差异,差异性分析回答:不同人群、不同条件、不同时间,在某个指标上是否存在显著差异? 比如:
- 男生和女生的学习成绩有没有差别?
- 培训前和培训后,能力有没有提升?
- 不同年级的学生,焦虑水平是否不一样?
统计学里笔者遇到最多的三种差异性分析方法:
1. 独立样本 t 检验
适用于两组完全不同的人/对象,比较的是两群互不相关的人。
如男生 vs 女生的学习成绩;实验组 vs 对照组的效果
2. 配对样本 t 检验
适用于同一组人,测两次,比较的是同一群人在不同时间的变化。
如培训前 vs 培训后;干预前 vs 干预后
3. 方差分析(ANOVA)
适用于三组及以上组别比较,当组别 ≥3 时,独立样本t 检验就不再使用了,要用ANOVA
如大一、大二、大三、大四的差异;低学历、中学历、高学历的差异
9. 完整案例
短视频平台算法推荐对用户信息茧房程度的影响机制
Q1 性别:男 女
Q2 收入 3k- 3k+ 5k+ 7k+ 9k+
请根据你的实际情况,选择最符合的选项:
推荐个性化程度 X
- 平台推送的内容大多是我感兴趣的类型
- 平台很少给我推陌生领域的内容
- 平台推送的创作者是我常看的类型
- 平台会根据我之前的互动推相似内容
信息接触窄化 M1
- 我日常看的内容观点比较单一
- 我很少接触和自己立场不同的信息
- 我了解的领域集中在固定几类
- 我接收的信息类型和范围比较局限
认知舒适感 M2
- 刷到符合我偏好的内容会让我很放松
- 看到认同的观点时,我会觉得很愉悦
- 看熟悉类型的内容让我很有安全感
- 平台推的内容总能让我觉得"合心意"
- 刷到与我想法一致的内容时,我会感到很有共鸣
信息茧房程度 Y
- 我觉得自己对某些事物的认知越来越固化
- 遇到不同观点时,我很难接受
- 我不太愿意主动了解新领域的信息
- 我觉得自己的认知被"困住"在固定范围里
- 我周围的人(线上)和我观点都差不多
信息批判意识 A
- 看到内容时,我会先质疑它的真实性
- 我会主动验证看到的信息是否可靠
- 遇到观点类内容,我会思考它的片面性
研究假设
根据该领域的相关理论和参考文献,提出以下假设:
H1:X与Y呈正相关
H2:M1在X与Y之间起中介作用
H3:M2在X与Y之间起中介作用
H4:A调节M1与Y之间的关系
H5:A调节M2与Y之间的关系
H6:不同收入群体在Y上存在显著差异
X为自变量,Y为因变量,M1/M2为中介变量,A为调节变量:
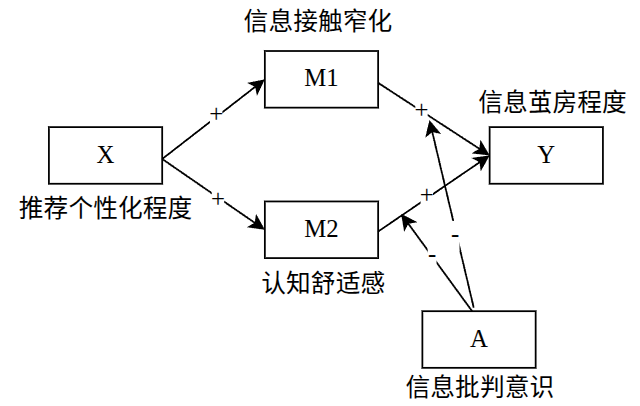
期望的研究结论
- 相关性分析:M1与X、Y显著正相关,M2与X、Y显著正相关
- 中介效应:X→M1→Y、X→M2→Y,M1和M2在X与Y间起正向中介作用
- 调节效应:A在M1与Y的关系中起负向调节作用,A在M2与Y的关系中起负向调节作用
- 方差分析:以收入为分组变量,在因变量Y上检验差异;期望高收入群体(5000+)在Y维度得分低于低收入群体(5000-)
10. 下一步
现在你已经理解了基本概念,可以开始使用系统了:
- 数据生成教程:查看详细使用指南
- Kano模型教程:查看Kano模型使用指南
- 配对T检验:查看配对样本T检验指南
笔者并非统计专业出身,略懂统计皮毛,文中内容都是自己一点点摸索总结的 “实用版” 理解,难免有不够严谨的地方,还请读者多多包涵!
祝顺利