数据生成使用指南
本模块专用于具有复杂统计分析需求的问卷,主要用于用户通过可视化界面设置量表水平、样本量、维度关系等参数,自动生成符合研究设计的模拟数据,并支持数据下载与智能解读功能。 对于Kano模型,请查看Kano模型使用指南。
核心参数说明
- 量表水平:设置量表的评分等级(4-8 级),默认值为 5 级(如常见的 "非常不同意" 到 "非常同意" 5 级评分)
- 样本量:设置需要生成的样本数量(建议 200-2000 之间)
- 随机种子:用于复现结果的随机数种子,相同种子 + 相同设置可生成完全相同的数据
1. 维度配置与关系建立
维度配置用于定义研究中的核心变量(维度),是数据生成的基础。
1.1 核心维度设置
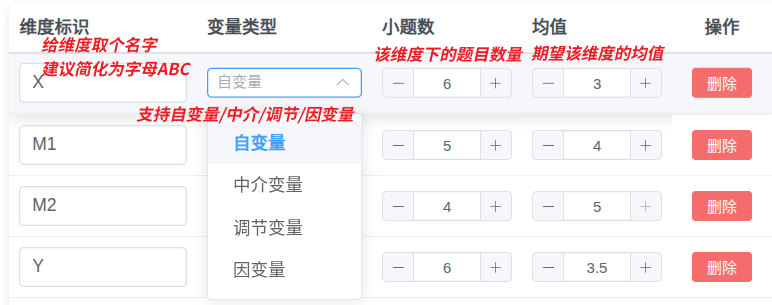
- 维度标识:变量简称,随便取个名字(如 "A"、"B"、"IV"、"DV"等)
- 变量类型:在整体研究中该变量的定位,支持自变量/中介/调节/因变量
- 小题数:该维度包含的题目数量(3-10 题)
- 均值:该维度的平均得分(需在 1 - 量表水平之间)
1.2 维度关系配置
用于定义变量之间的影响关系,系统会根据此配置生成具有预期相关性的数据。
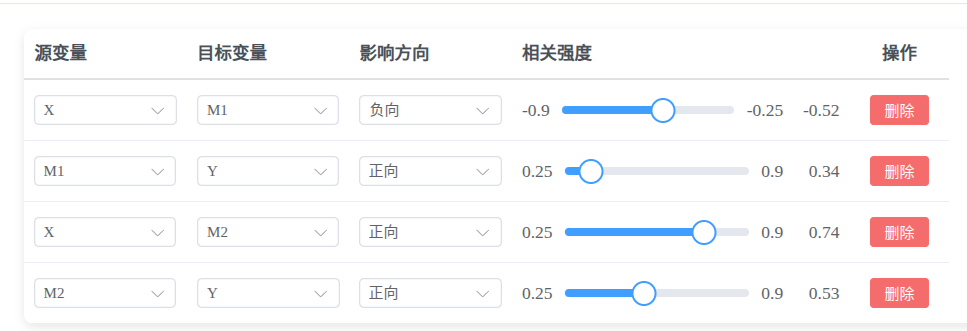
- 源变量:影响的发出者(如 自变量)
- 目标变量:被影响的变量(如 因变量或中介变量)
- 影响方向:正向 或 负向,决定源变量&目标变量之间的相关性正负。
2. 人口统计学变量与差异效应
2.1 人口统计学变量设置
用于添加性别、年龄、学历等人口统计学变量。这些变量可以用于后续的差异性检验。

2.2 差异效应设置 (方差分析模拟)
用于设置不同人口学分组在特定维度上的差异,以模拟统计学中的显著差异(ANOVA或T检验)。
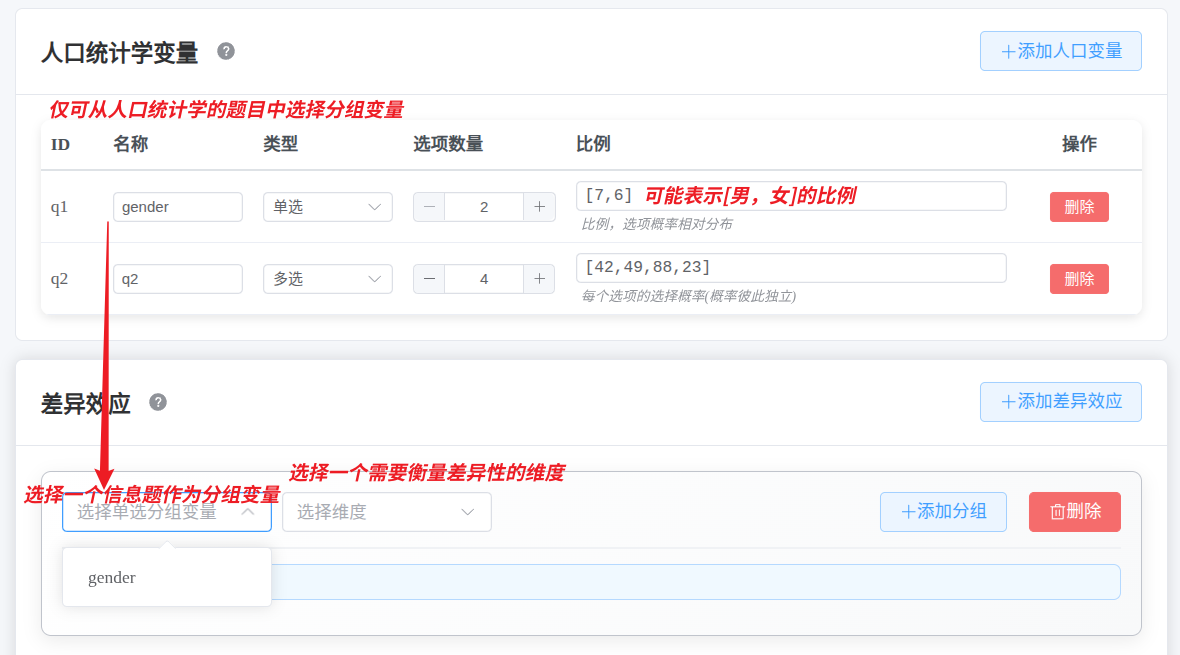
需要将同组别的选项拖入到同一个分组框中。
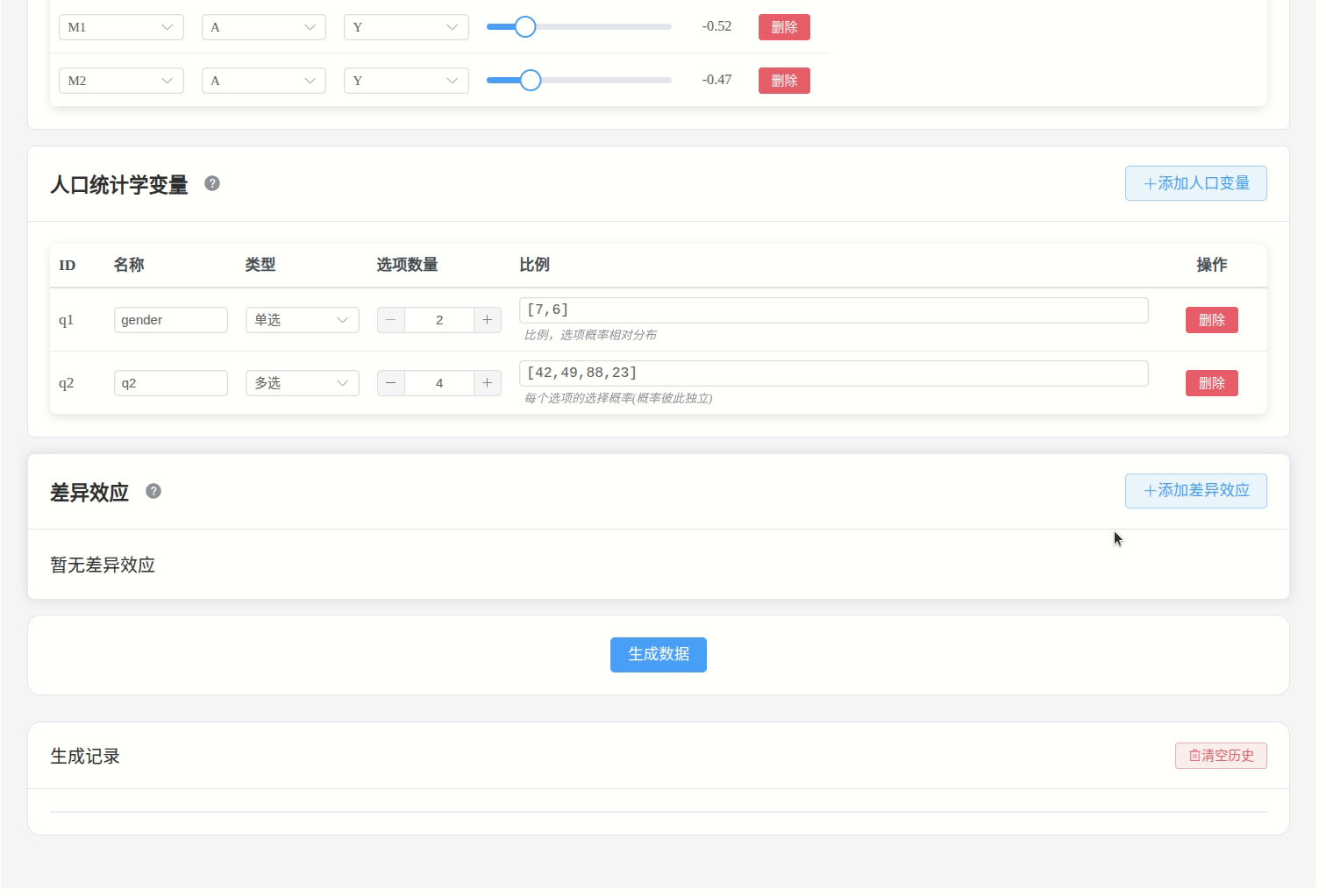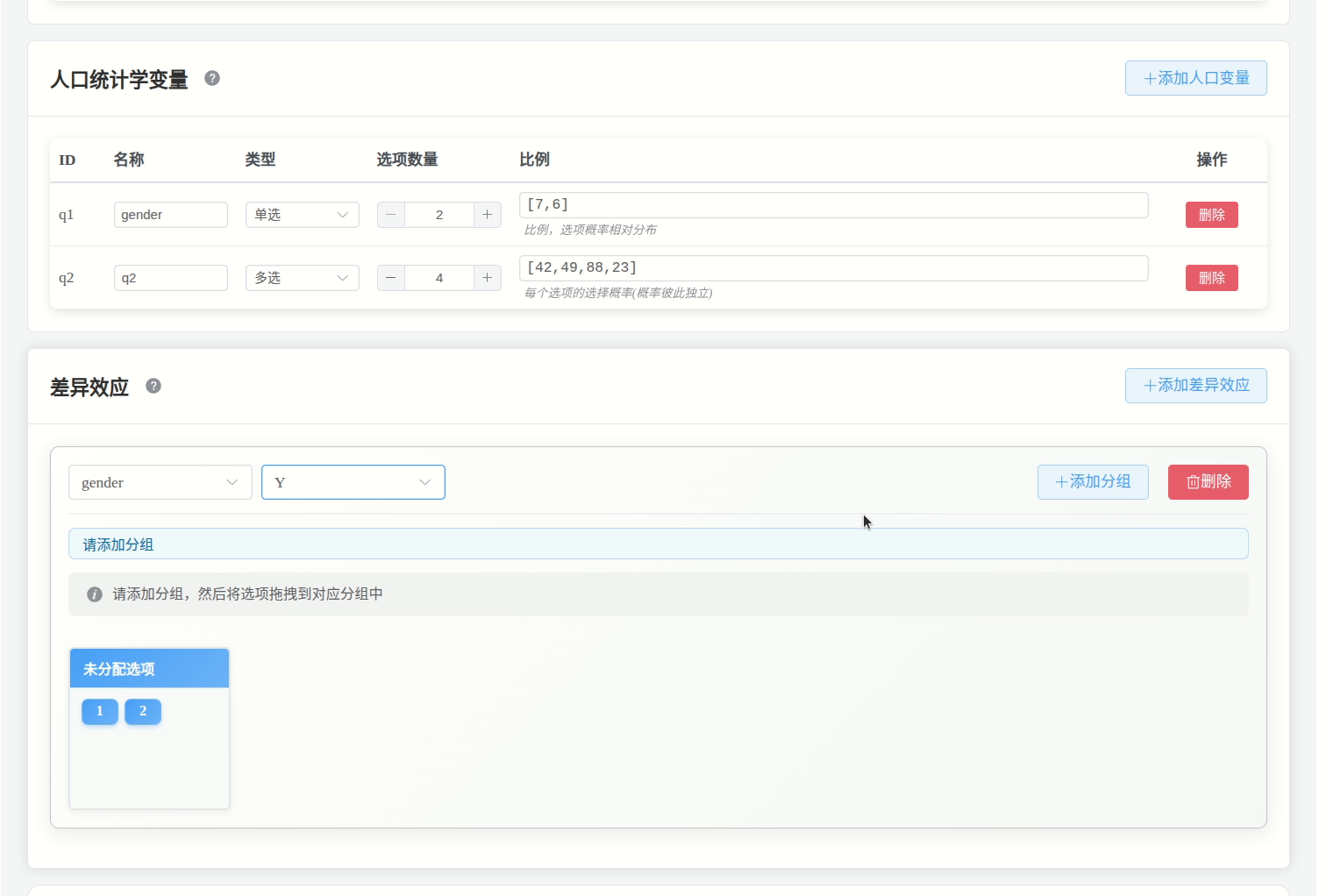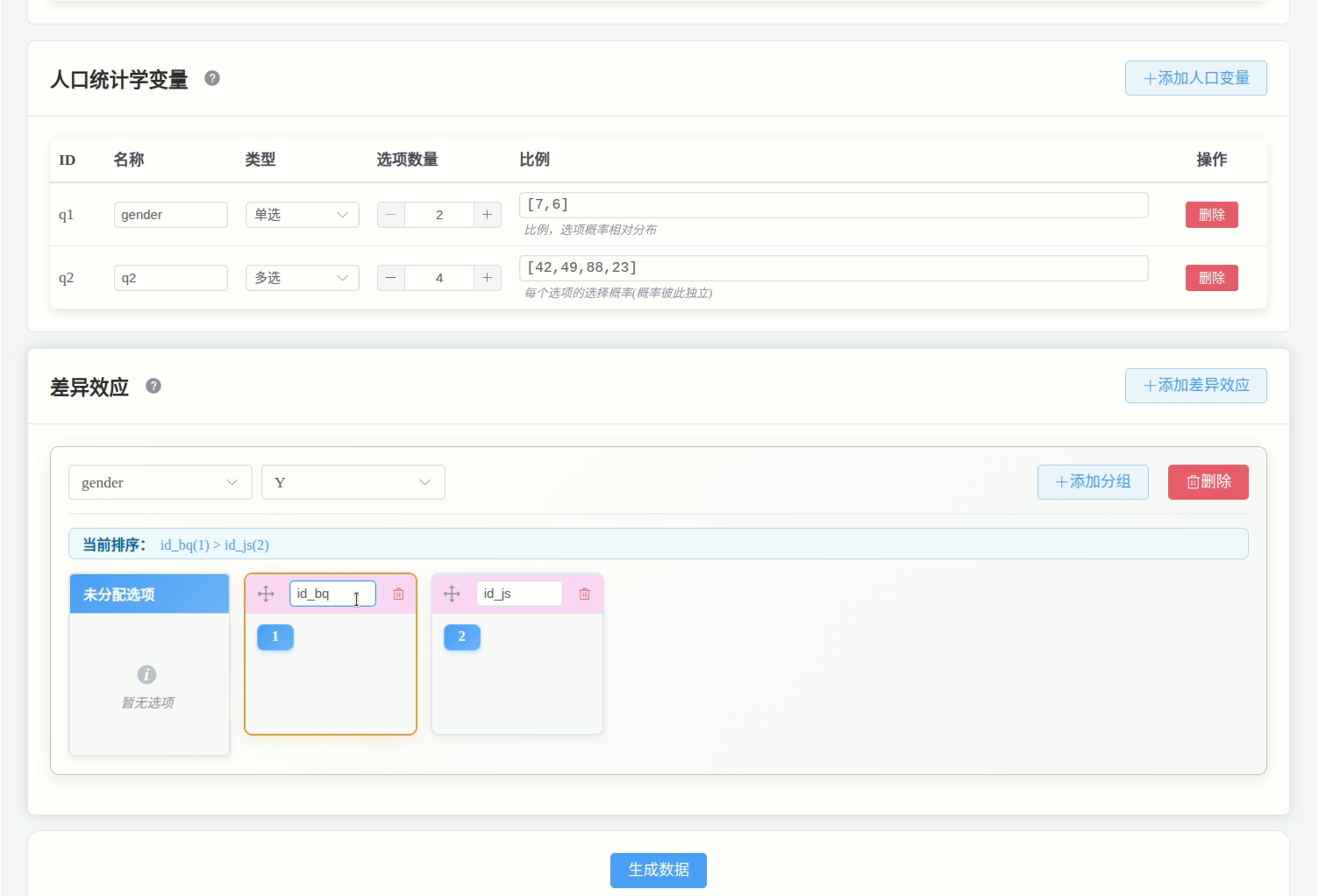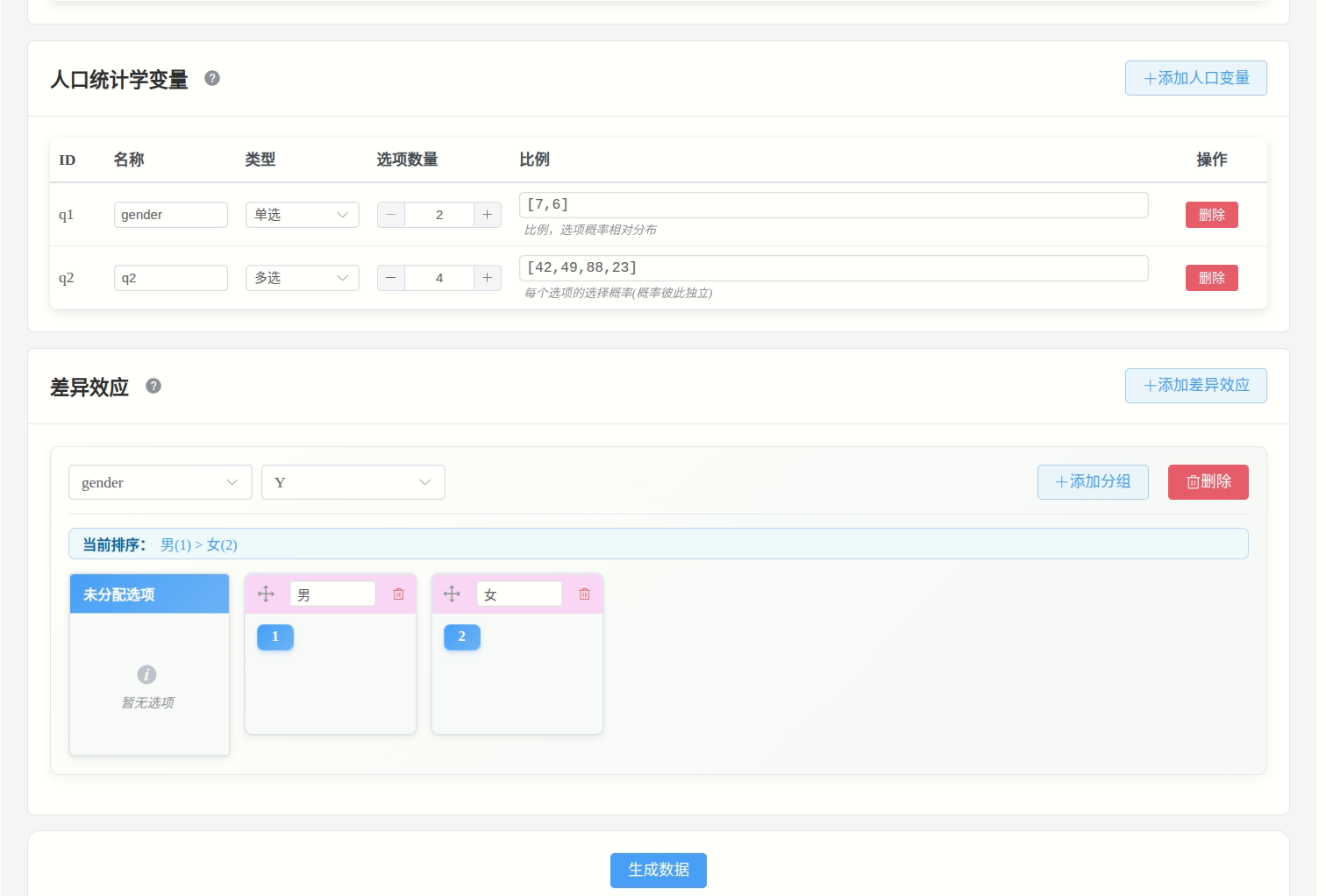
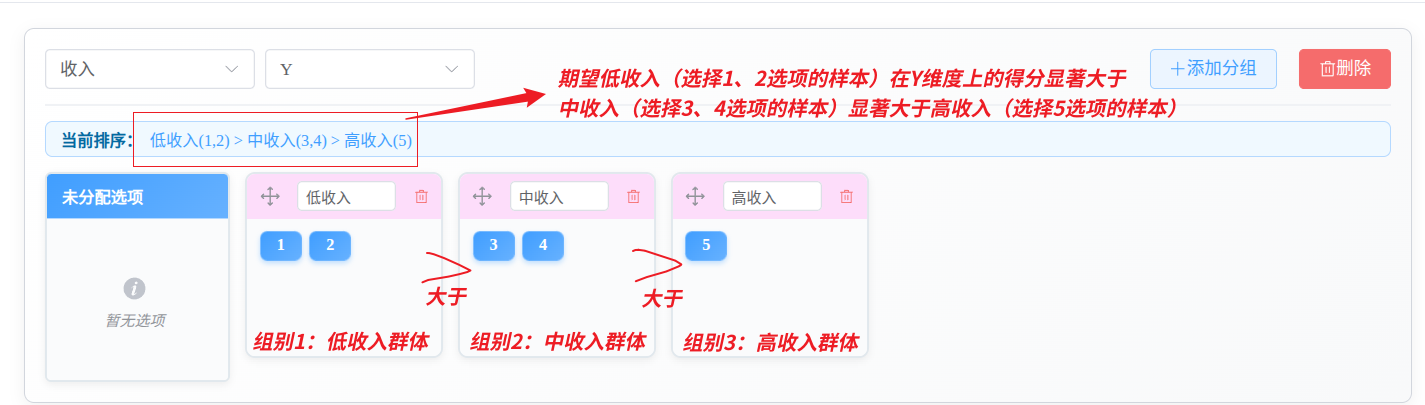
例如:当一个题目为:“你的月收入为?”,选项分别为:3000-, 3000+, 5000+, 7000+, 9000+; 可以如下设置:

3. 数据生成、分析与下载
配置完成后,就可以点击 "生成数据" 开始生成了。
生成完毕后系统会返回数据的分析结果,包括:
- 信度 Cronbach's alpha 系数
- 效度 KMO 值和 Bartlett 球形检验显著性
- 相关性 系数及其 p 值
- 方差分析 显著性、回归分析、中介分析、描述统计
如果你觉得数据可以接受(如 信度 > 0.7,关系显著),那就可以点击下载文件直接下载了;如果你觉得数据欠佳,可以尝试更换随机种子并重新生成,直到满意为止。
4. 完整案例
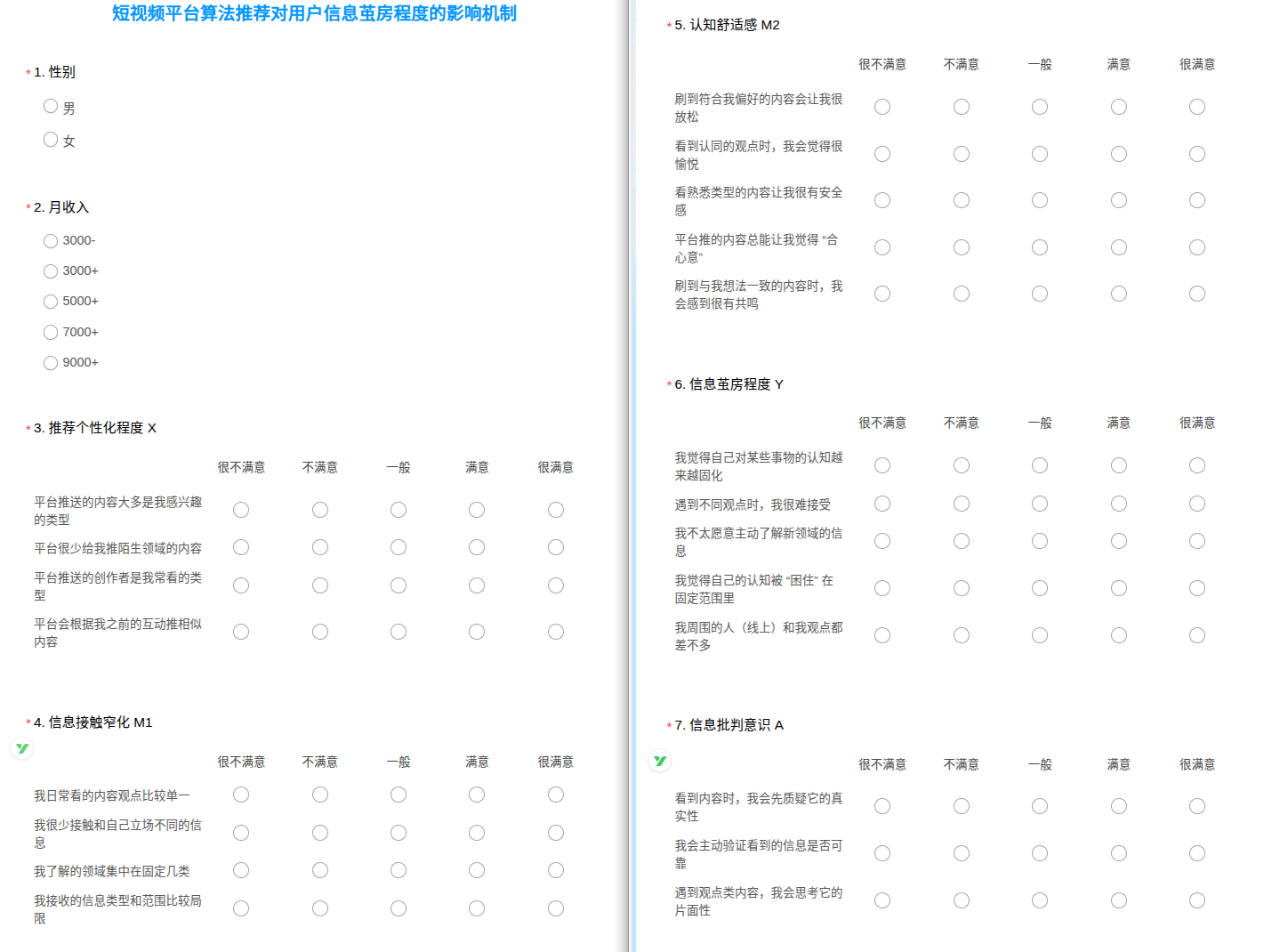
以“短视频平台算法推荐对用户信息茧房程度的影响机制”为例,一共 2 个人口统计学题目,5 个维度。
问卷结构
- 第1题:性别
- 第2题:收入
- 量表共5个变量:X、M1、M2、Y、A,均为5分量表
- X,M1,M2,Y,A 的题目数分别为4题,4题,5题,5题,3题
假设模型如下,X 为自变量,Y 为因变量,M1/M2 为中介变量,A 为调节变量:
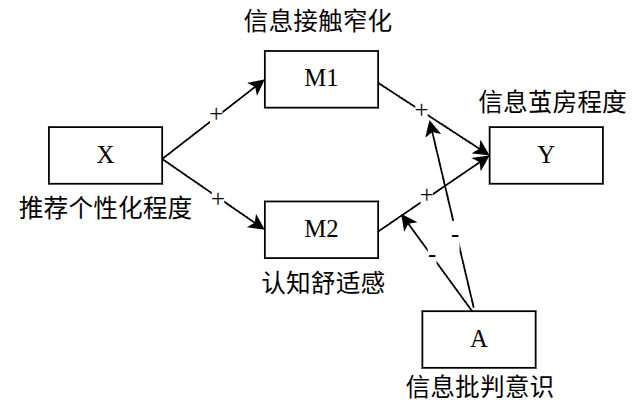
以下是期望数据可以满足的结论:
- 相关性分析:M1与X、Y显著正相关,M2与X、Y显著正相关
- 中介效应:X→M1→Y、X→M2→Y,期望M1在X与Y间起正向中介作用,M2在X与Y间起正向中介作用
- 调节效应:A 在 M1 与 Y 的关系中起负向调节作用,A 在 M2 与 Y 的关系中起负向调节作用
- ANOVA方差分析: 以第2题(收入)为分组变量,在因变量Y上检验差异;期望高收入群体(收入5000+)在Y维度得分 < 低收入群体(收入5000-)
那么配置如下: 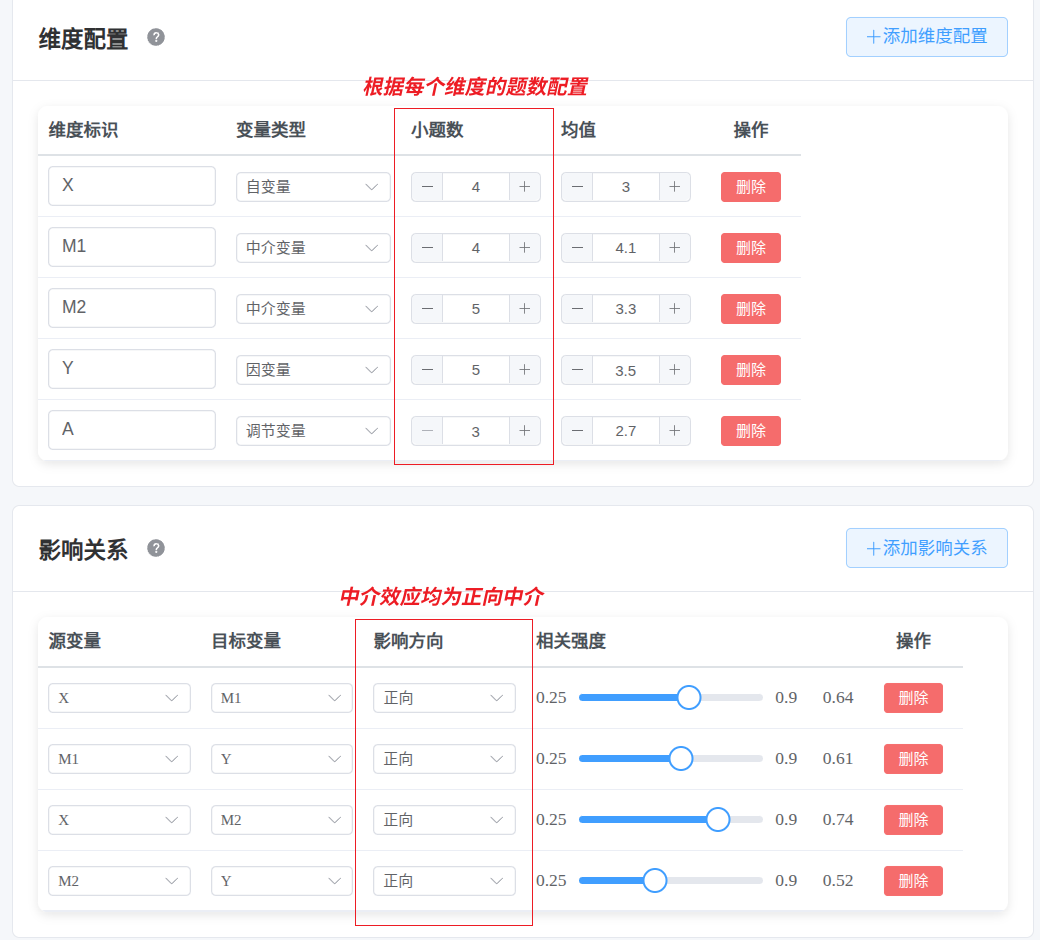
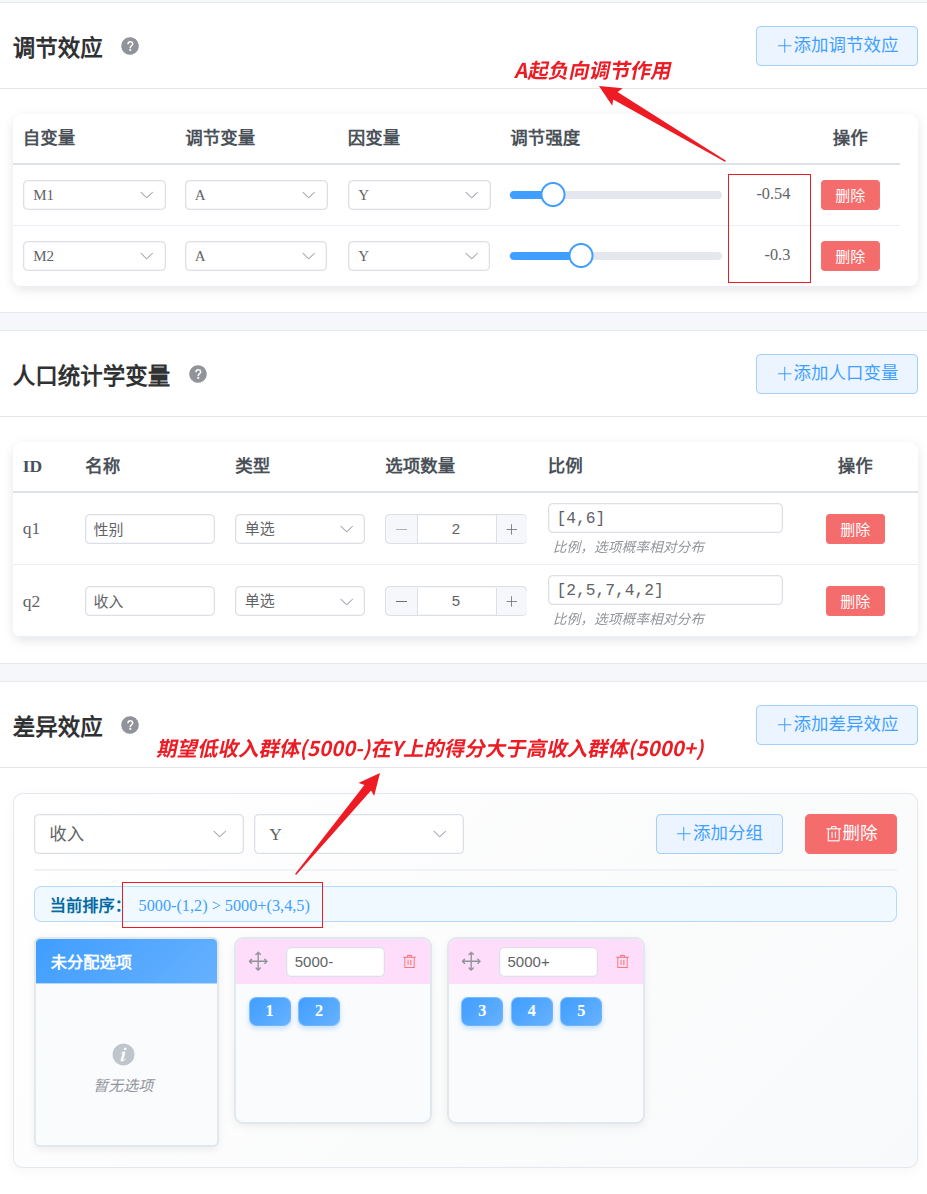
生成之后,系统会输出数据各项结果,包括描述性统计分析、信度、效度、方差等,用于验证生成的数据是否符合研究假设。
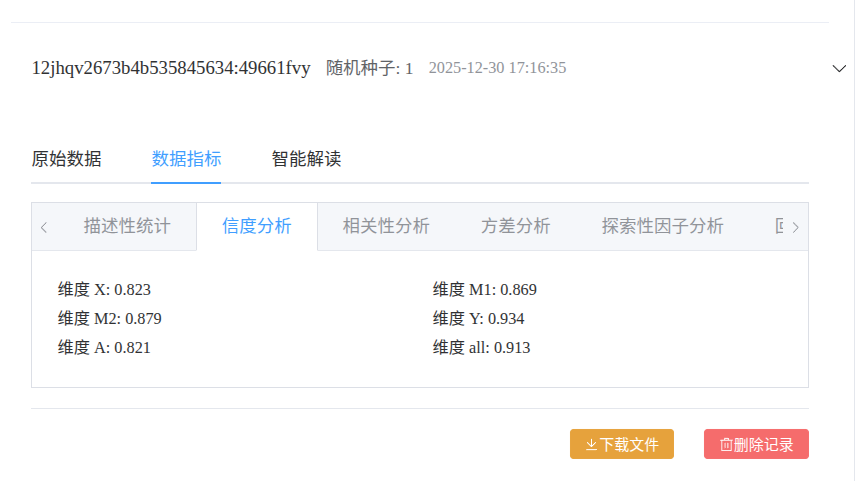 结果与SPSS的分析结果保持一致。
结果与SPSS的分析结果保持一致。  中介效应:
中介效应: 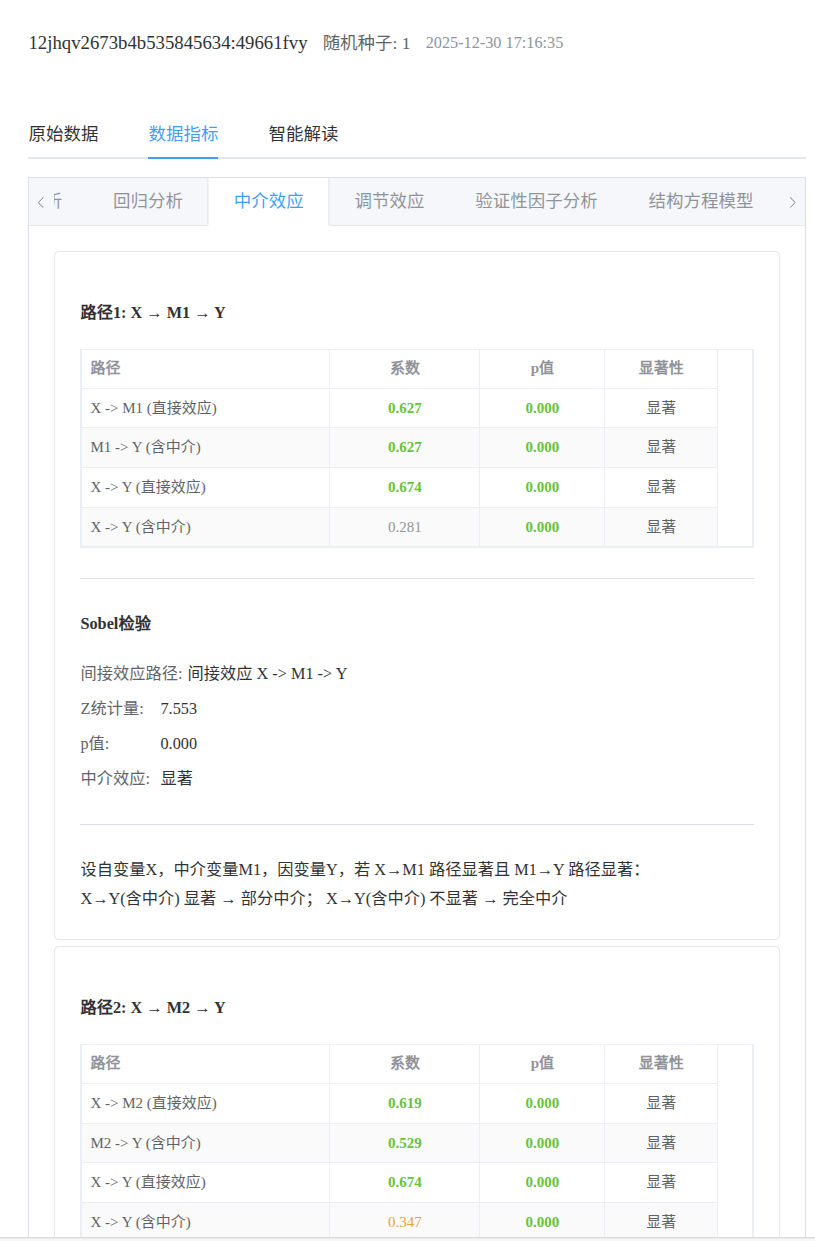 调节效应:
调节效应: 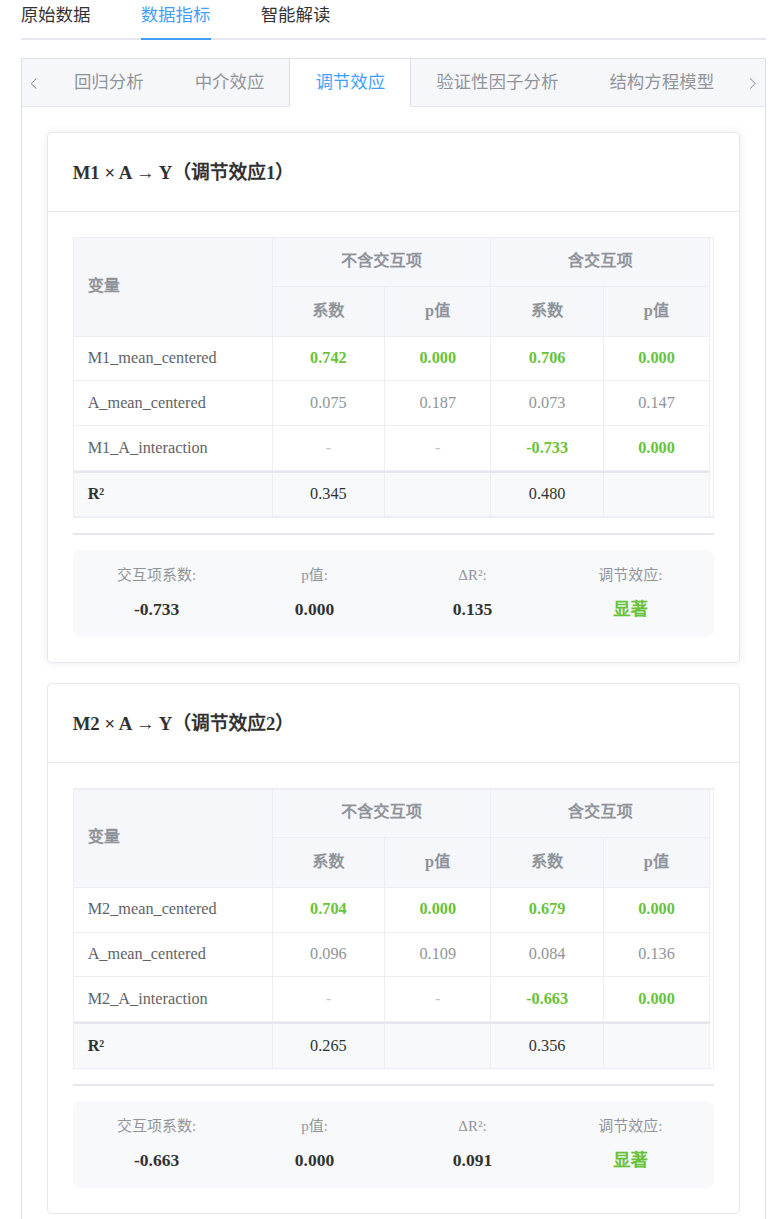 ANOVA方差分析:
ANOVA方差分析: 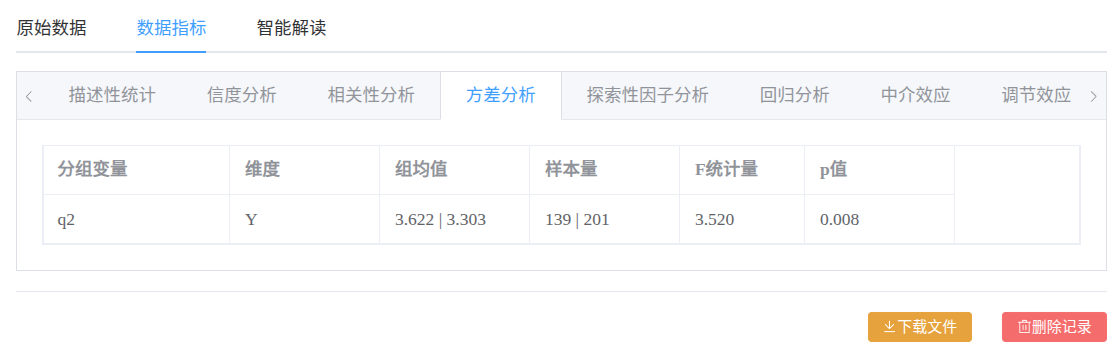 所有指标均可在spss中复现。祝顺利。
所有指标均可在spss中复现。祝顺利。