Kano模型简介
Kano模型是一种用于产品功能分类和优先级分析的工具,能够帮助识别哪些功能对用户满意度影响最大,从而指导产品开发和资源分配。Kano模型将产品功能分为五类:
| 类型 | 名称 | 说明 | 提供时 | 不提供时 |
|---|---|---|---|---|
| M | 必备特性 | 必须具备的功能 | 无影响 | 非常不满意 |
| O | 期望特性 | 用户期望的功能 | 满意 | 不满意 |
| A | 魅力特性 | 用户意想不到的功能 | 非常满意 | 无影响 |
| I | 无差异特性 | 用户不在意的功能 | 无影响 | 无影响 |
| R | 反向特性 | 提供时会降低满意度的功能 | 不满意 | 满意 |
| Q | 存疑特性 | 受访者没有很好理解某问项 | 满意 | 满意 |
kano生成器:http://sugarblack.top/kano
1. 基本配置
- 样本量:需要生成的样本数量(建议 200-2000 之间)
- 随机种子:一个随机数字,用于控制随机数生成:相同种子 + 相同配置 = 完全相同的数据
- 如果对生成的数据不满意,可以修改种子重新生成不同数据;满意后请记录种子,以便下次复现结果
2. 功能配置
功能配置是 Kano 模型的核心,用于定义需要分析的产品功能及其特性类型。 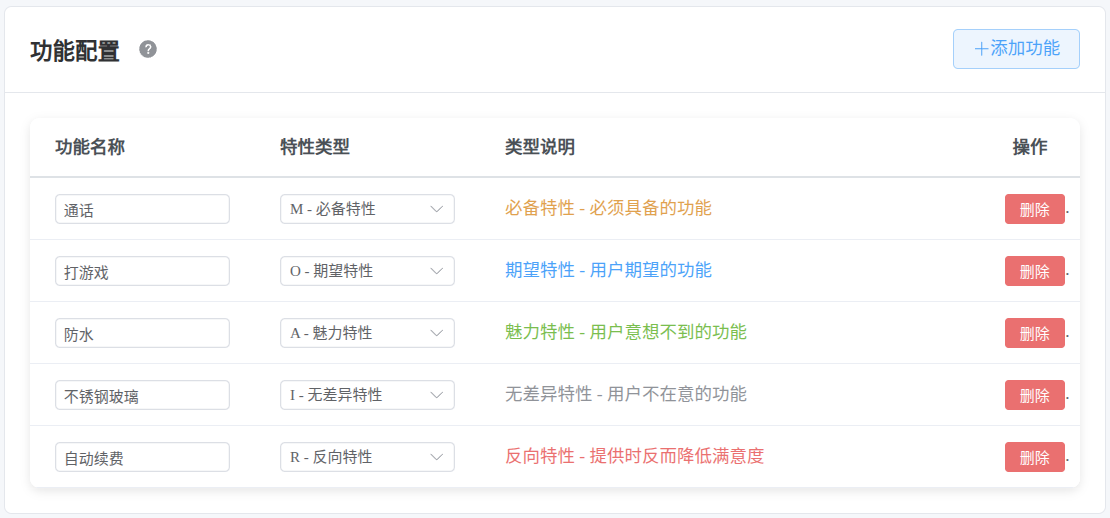
2.1 添加功能
点击"添加功能"按钮,在表格中新增一行功能配置。
2.2 功能名称
输入功能的名称标识,如"快速搜索"、"个性化推荐"等。
2.3 特性类型选择
为每个功能选择其所属的 Kano 特性类型:
M - 必备特性:必须具备的功能,缺少时会非常不满意;如登录功能、数据保存、基本操作
O - 期望特性:用户期望的功能,提供越多越满意;如响应速度、界面美观、操作便捷
A - 魅力特性:用户意想不到的功能,提供时会很高兴;如智能推荐、个性化定制、创新交互
I - 无差异特性:用户不在意的功能;如某些边缘功能、过度复杂的设置
R - 反向特性:提供时反而会降低满意度;如强制广告、复杂验证、冗余功能
TIP
系统会根据您设置的特性类型生成模拟数据,并分析实际生成的数据与期望类型的匹配程度。
3. 人口统计学变量
人口统计学变量用于描述样本特征,如性别、年龄、学历等。
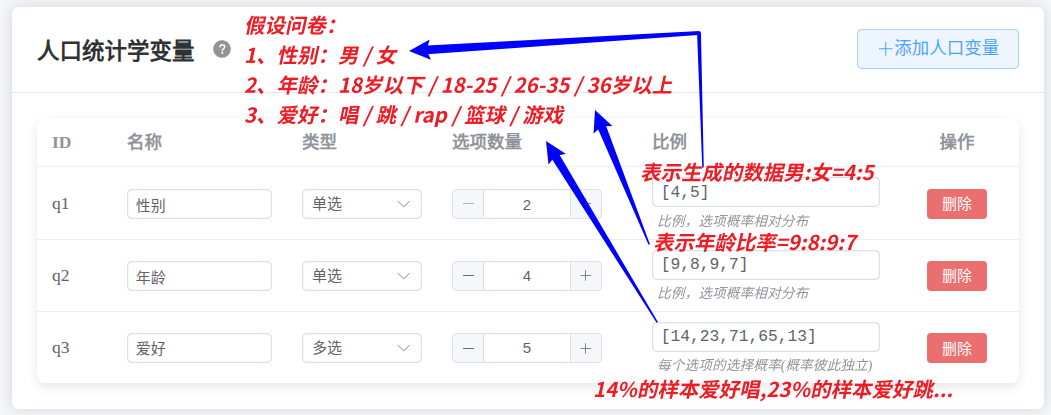
3.1 添加人口变量
点击"添加人口变量"按钮,添加需要的人口统计学变量。
3.2 变量配置
- 名称:变量名称(如性别、年龄、学历)
- 类型:单选或多选
- 选项数量:该变量包含的选项数量
- 比例:格式如
[8,0,6,7,4],可以有小数
3.3 比例说明
- 单选题:比例代表最终数据占比,如
[2,6,9]就是 2:6:9 - 多选题:比例代表单个选项的选择概率(百分比),如
[2,6,9]是每个选项分别有 2%、6%、9% 的概率被选;单个比例范围0-100,建议多选比例和至少>=100
重要提醒
- 请在英文输入法下输入参数,使用
,、[]、""等符号 - 不能全为 0 或输入无效内容(如全空、负数、非法字符)
- 单选题的比例和应 ≥ 1,多选题比例和 ≥ 100
4. 填空题配置
- 随机数字:设置数值范围和小数位数
- 随机日期:设置年月日范围
- 随机姓名:系统自动生成中文姓名
- 随机号码:系统自动生成手机号码
- 自定义文本:手动编辑文本列表
- 答案之间以 3 个井号
###分割,如:无###没有###期望加大预算###无###没什么 - 在生成每个样本时,系统将随机选择一条作为答案
- 答案之间以 3 个井号
5. 数据生成与分析
配置完成后,点击"生成数据"按钮开始生成,系统会显示本次生成的数据指标。
5.1 功能分析
每个功能的 Kano 特性分类及系数分析:
| 指标 | 说明 |
|---|---|
| 期望类型 | 设置的 Kano 特性类型 |
| 实际类型 | 根据生成数据计算的实际类型 |
| 满意度系数 | Better 系数,表示提供该功能对满意度的影响 |
| 不满意度系数 | Worse 系数,表示不提供该功能对满意度的影响 |
5.2 信度分析
包含正负向问题的 Cronbach's alpha 系数【1】
5.3 Kano 模型分析结果
- 各功能在 A、O、M、I、R、Q 六个维度的占比
- Kano 定位
- Better 系数
- Worse 系数
5.4 Better 和 Worse 系数解读
Better 系数:表示提供该功能时,用户满意度的提升程度
- 系数越高,提供该功能带来的满意度提升越大
- 魅力特性(A)通常有较高的 Better 系数
Worse 系数:表示不提供该功能时,用户满意度的下降程度
- 系数越低(绝对值越大),不提供该功能带来的满意度下降越大
- 必备特性(M)通常有较低的 Worse 系数
6. 完整案例
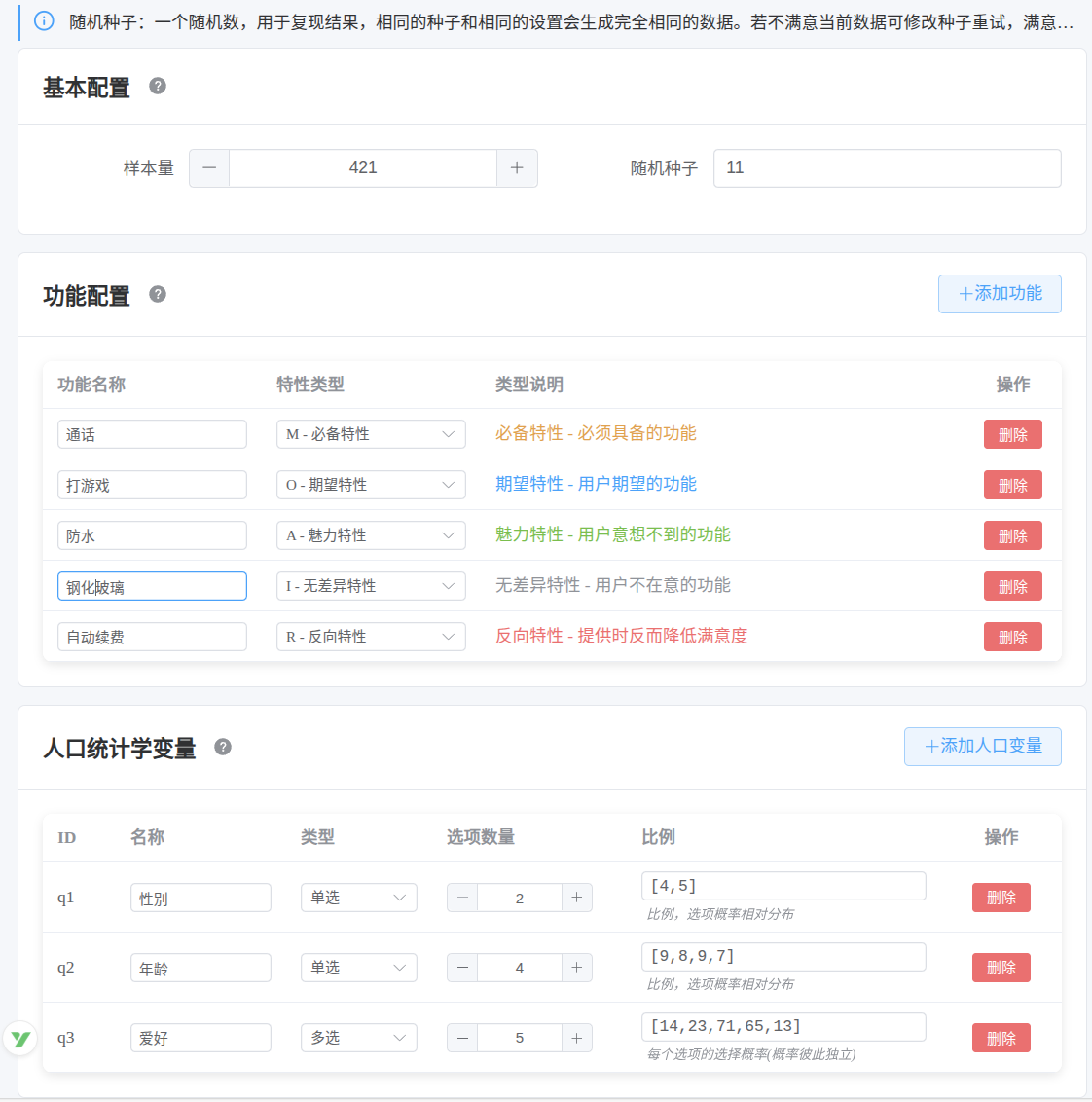
以某手机功能优化为例,分析 5 个核心功能。
6.1 问卷结构

假设期望收集421份样本,且针对每个功能,期望特性如下:
- 手机通话:M(必备)
- 手机游戏:O(期望)
- 手机防水:A(魅力)
- 钢化玻璃:I(无差异)
- 自动续费:R(反向)
6.2 配置示例
6.3 生成结果
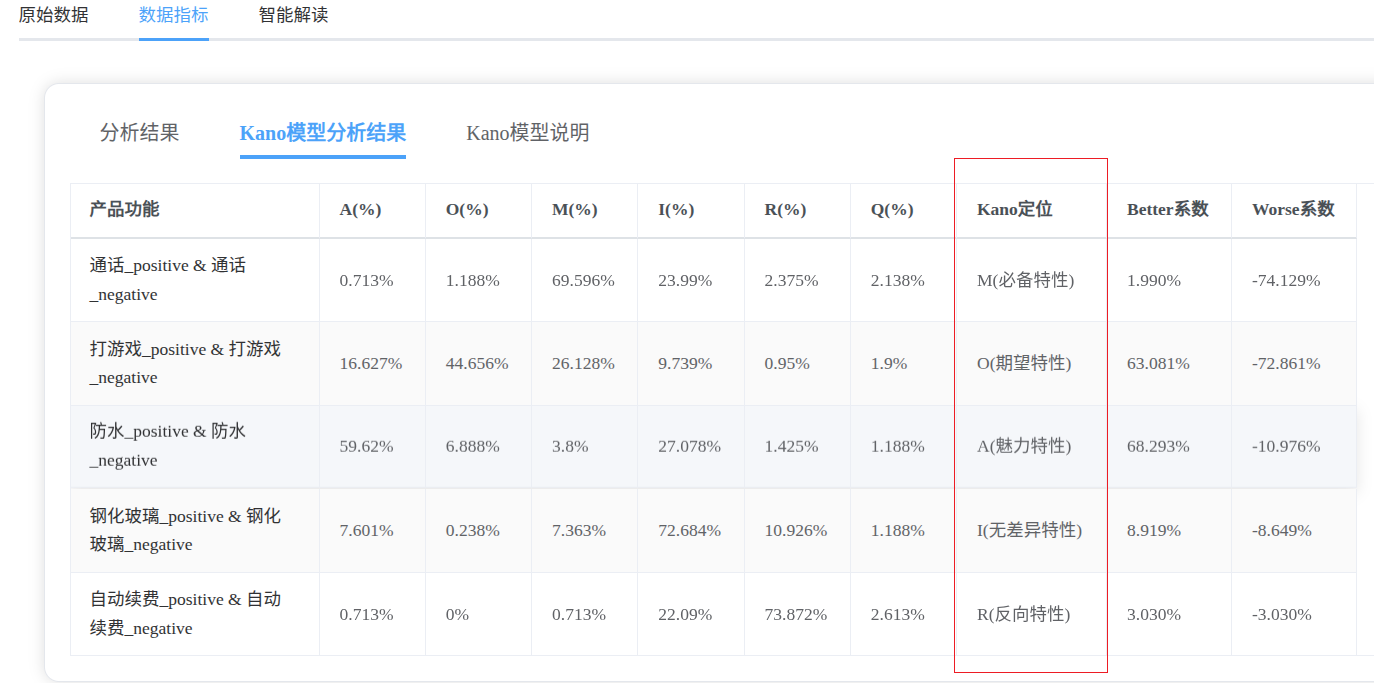
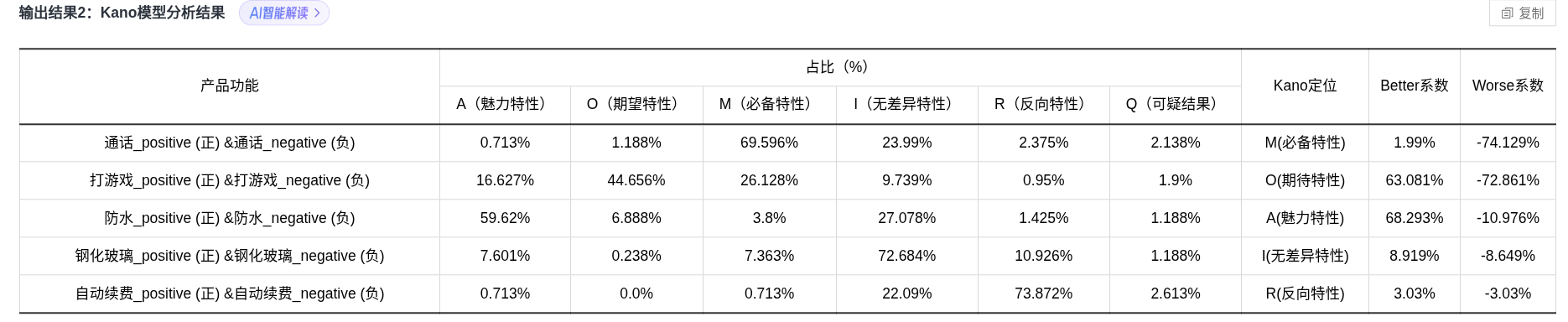
功能分析结果
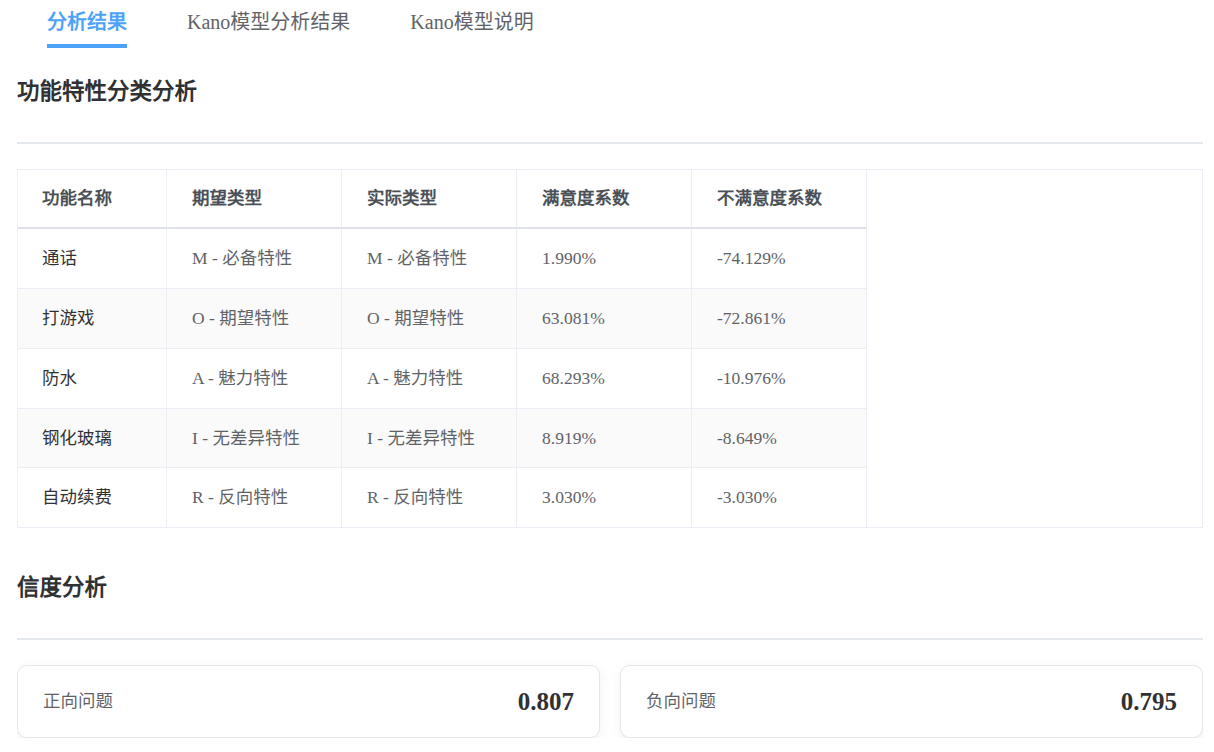
分析结果解读
- 正负向问题的信度[1]分别为:0.807,0.795
- 每一个功能的kano定位均正确
且数据可在spss/spsspro/spssau中复现:
6.4 结果解读
该Kano模型分析结果显示,不同产品功能在用户需求分类中呈现显著差异。
通话功能被归类为必备特性(M),其69.596%的占比表明绝大多数用户认为该功能不可或缺,Worse系数高达-74.129%进一步验证其缺失将导致严重不满,但Better系数仅1.99%说明其存在对满意度提升有限。
打游戏功能属于期望特性(O),44.656%的负面评价占比与26.128%的必备需求占比形成对比,63.081%的Better系数和-72.861%的Worse系数证实其双向影响力:提供该功能显著提升满意度,缺失则引发明显不满。
防水功能作为魅力特性(A)具有59.62%的高正向评价占比,68.293%的Better系数表明其能极大提升用户体验,而仅10.976%的Worse系数说明其缺失不会造成严重负面影响。
钢化玻璃功能被判定为无差异特性(I),72.684%的无差异需求占比与较低的Better(8.919%)和Worse(-8.649%)系数共同表明用户对其存在与否敏感度低。
自动续费功能呈现典型反向特性(R),73.872%的负面评价占比与3.03%的绝对Better-Worse系数值证实该功能会降低用户满意度。
所有功能的可疑结果(Q)占比均低于3%,表明数据可靠性较高。
各功能分类结果与Better-Worse系数呈现高度一致性:必备特性Worse系数绝对值显著高于Better系数,魅力特性则相反,期望特性双向系数均较高,无差异特性双向系数均较低,反向特性呈现负向影响,符合Kano模型理论预期。
【1】:朱璐,张悦,王康美,等.基于Kano模型的正常高值血压人群中医健康管理需求研究[J].护理研究,2026,40(01):53-59.